# Encoder-Decoder 有哪些应用?

机器翻译、对话机器人、诗词生成、代码补全、文章摘要(文本 – 文本)
「文本 – 文本」 是最典型的应用,其输入序列和输出序列的长度可能会有较大的差异。
Google 发表的用Seq2Seq做机器翻译的论文《Sequence to Sequence Learning with Neural Networks》
Seq2Seq应用:机器翻译 语音识别(音频 – 文本)
语音识别也有很强的序列特征,比较适合 Encoder-Decoder 模型。
Google 发表的使用Seq2Seq做语音识别的论文《A Comparison of Sequence-to-Sequence Models for Speech Recognition》

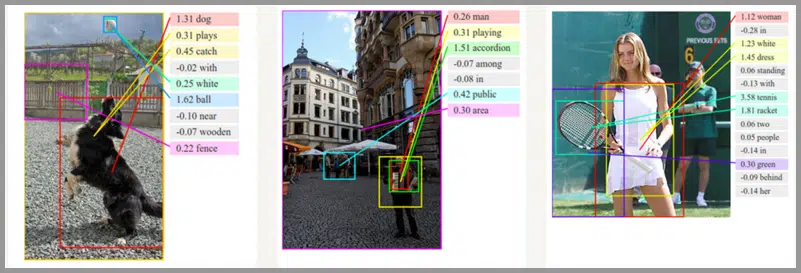
Seq2Seq应用:语音识别 图像描述生成(图片 – 文本)
通俗的讲就是「看图说话」,机器提取图片特征,然后用文字表达出来。这个应用是计算机视觉和 NLP 的结合。 图像描述生成的论文《Sequence to Sequence – Video to Text》
# Encoder-Decoder 的缺陷
上文提到:Encoder(编码器)和 Decoder(解码器)之间只有一个「向量 c」来传递信息,且 c 的长度固定。
为了便于理解,我们类比为「压缩-解压」的过程:
将一张 800X800 像素的图片压缩成 100KB,看上去还比较清晰。再将一张 3000X3000 像素的图片也压缩到 100KB,看上去就模糊了。
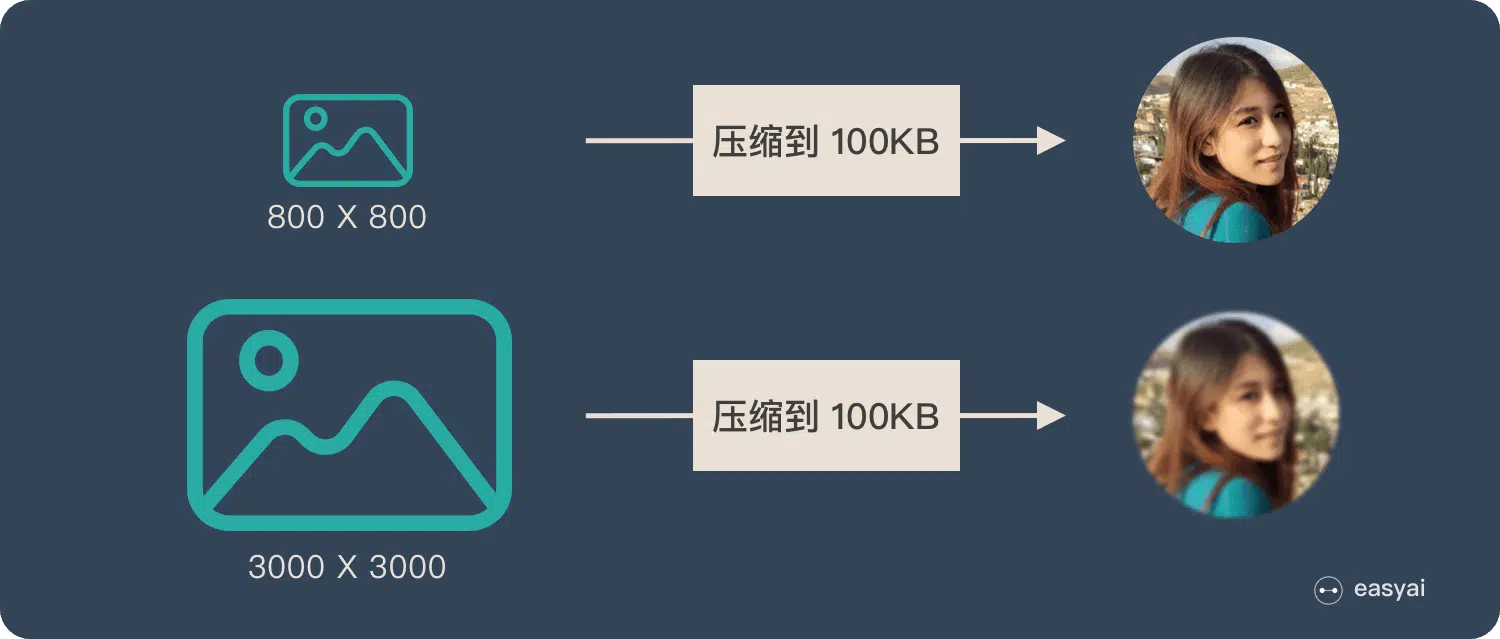
Encoder-Decoder的缺点:输入过长会损失信息 Encoder-Decoder 就是类似的问题:当输入信息太长时,会丢失掉一些信息。
# Attention 解决信息丢失问题
Attention 机制就是为了解决「信息过长,信息丢失」的问题。
Attention 模型的特点是 Eecoder 不再将整个输入序列编码为固定长度的「中间向量 C」 ,而是编码成一个向量的序列。引入了 Attention 的 Encoder-Decoder 模型如下图:
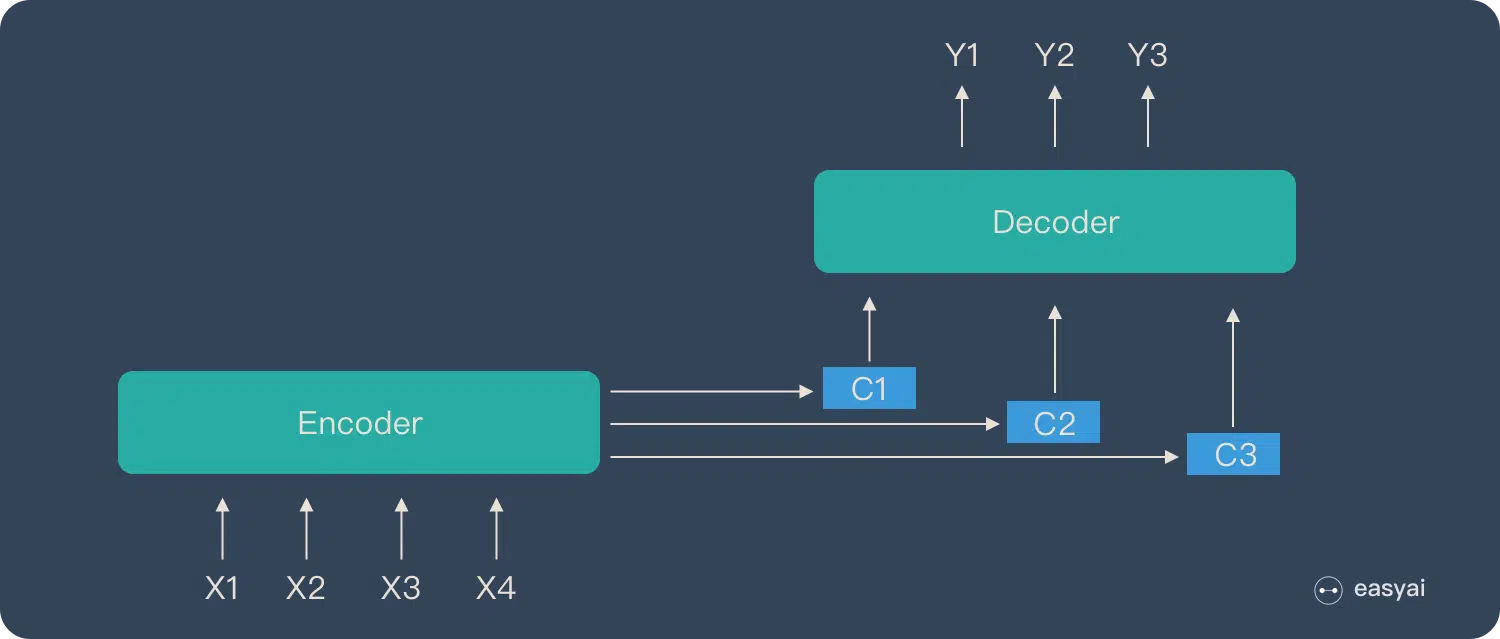
这样,在产生每一个输出的时候,都能够做到充分利用输入序列携带的信息。而且这种方法在翻译任务中取得了非常不错的成果。
Attention 是一个很重要的知识点,想要详细了解 Attention,请查看 (opens new window)